

What Is Retrieval-Augmented Generation? The Ultimate Guide to RAG
Artificial intelligence has changed the way we work, learn, and communicate. Today, Large Language Models (LLMs) can create content, write code, summarize information, and answer complex questions within seconds. However, traditional LLMs have a major limitation: they can sometimes generate incorrect or made-up information, a problem known as AI hallucination. To overcome this challenge, researchers and engineers developed a powerful approach called Retrieval-Augmented Generation (RAG).
So, what is Retrieval-Augmented Generation? RAG is a framework that improves LLM performance by allowing AI systems to retrieve information from external knowledge sources before generating an answer. Instead of depending only on its training data, an AI model can search trusted documents, databases, or other sources and use that information to create more accurate and reliable responses. According to NVIDIA, RAG connects generative AI models with external data sources, helping them deliver more relevant and context-aware responses. You can explore NVIDIA’s explanation of how generative AI models use external knowledge sources to improve accuracy for a deeper understanding of this approach. NVIDIA explanation of RAG and external knowledge sources
This guide explores how RAG works, its main stages, key benefits, and how it compares with traditional LLMs. Understanding RAG is essential for developers and businesses that want to build smarter, safer, and more trustworthy AI applications.
What Is Retrieval-Augmented Generation? The Core Mechanics
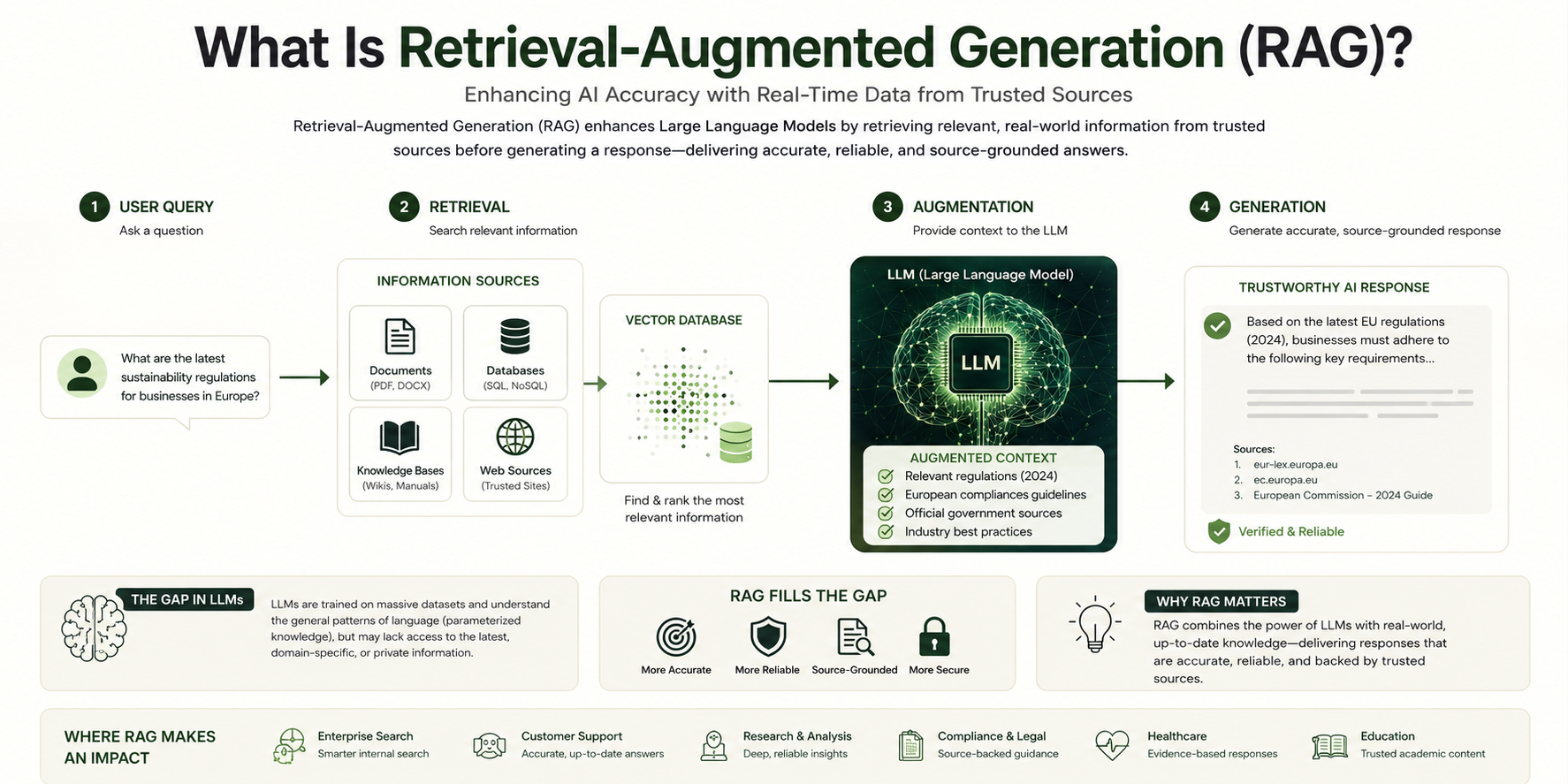
So, how does this framework solve these problems? Think of RAG as turning that closed-book exam into an open-book test. Instead of guessing the answer, the model receives a search engine that scours a specific database for relevant facts before formulating a response.
The system works by pairing a generator (the LLM) with a retriever (an external search tool). When a user inputs a prompt, the retriever finds matching documents within a custom data repository. The system then bundles those source documents together with the user’s original query and hands the entire package to the LLM. As a result, the model reads the provided text and extracts the exact information needed to answer the user perfectly.
Furthermore, this method eliminates the need to constantly retrain or fine-tune massive neural networks. You simply update the text documents in your database, and the AI immediately gains access to the fresh data.
The Four Vital Stages of a RAG Architecture
Building an enterprise-ready RAG system requires a structured pipeline. The process involves transforming raw data into actionable knowledge that an AI can read instantly. Developers break this pipeline down into four distinct phases.
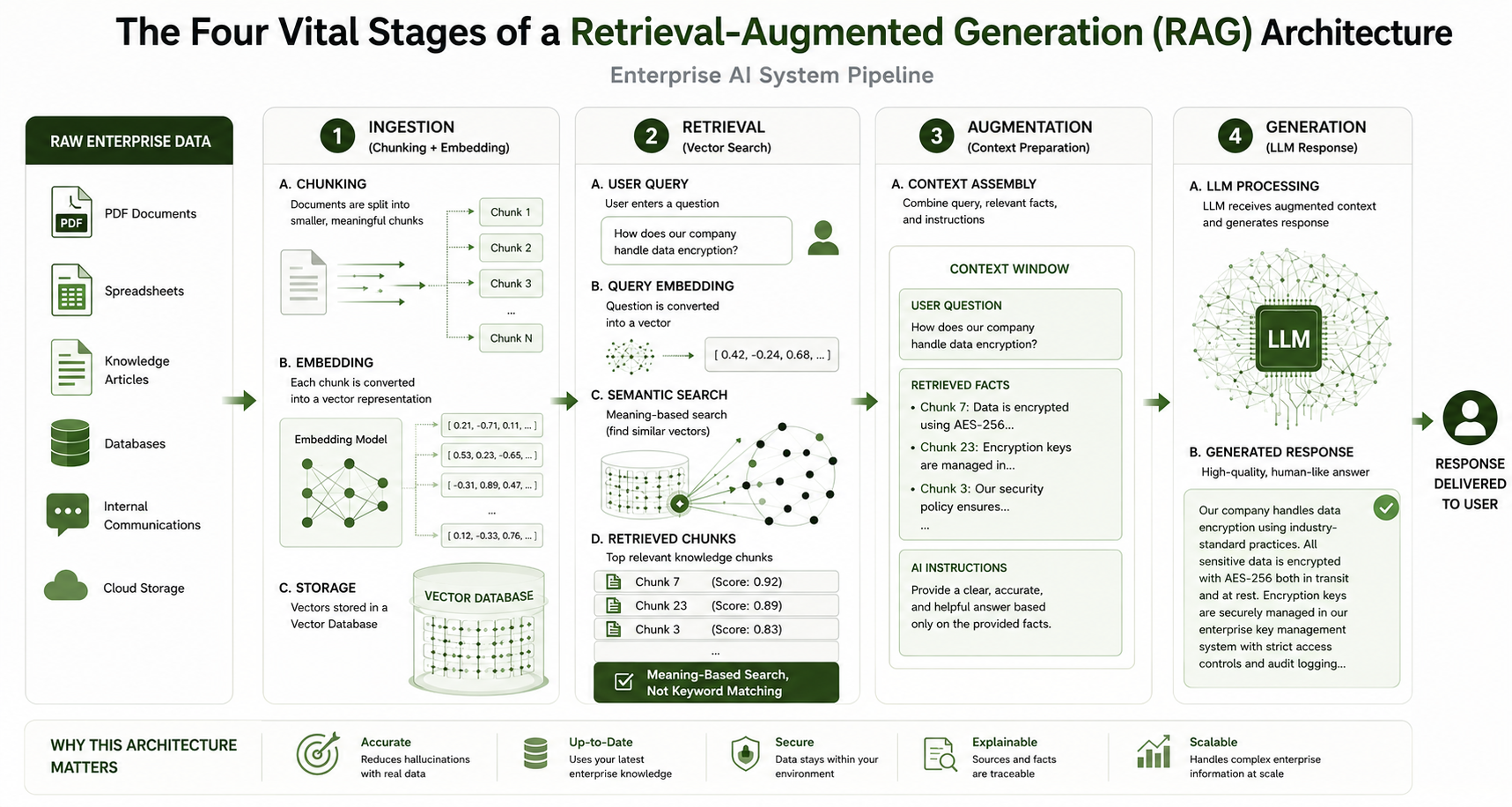
1.The Ingestion Stage
Before an AI can retrieve information, you must prepare your data. First, developers gather documents like PDFs, spreadsheets, and knowledge base articles. The system breaks these large files into smaller, readable pieces called chunks. Next, an embedding model converts these chunks into mathematical strings called vectors, which capture the semantic meaning of the text. Finally, these vectors are stored in a dedicated vector database.
2. The Retrieval Stage
This stage begins the moment a user asks a question. The system converts the user’s query into a vector using the same embedding model. It then performs a mathematical search across the vector database to find the text chunks that most closely match the intent of the query. Instead of just matching exact words, it finds matching concepts.
3. The Augmentation Stage
Once the system identifies the most relevant text chunks, it prepares them for the language model. The system creates a comprehensive prompt that combines the retrieved facts, the user’s initial question, and specific instructions on how to behave. For example, it might instruct the AI to only use the provided text and to say “I don’t know” if the answer isn’t present.
4. The Generation Stage
In the final phase, the augmented prompt is delivered to the LLM. The model reads the context chunks, synthesizes the information, and writes a natural, human-like response. Because the text contains the raw facts, the model does not have to guess, resulting in a highly accurate output.
The Core Differences Between LLM and RAG
Understanding the distinction between a standalone LLM and a RAG setup is critical for planning any AI strategy. While they work together, they serve completely different functions in an application.
| Feature | Standalone LLM | RAG-Enabled System |
| Data Source | Static internal training data | Internal data plus dynamic external databases |
| Information Recency | Limited by the strict training cutoff date | Real-time updates based on database changes |
| Risk of Hallucination | High, especially on niche or new topics | Extremely low, as answers require source backing |
| Data Privacy | Cannot inherently access private company files | Securely connects to private internal repositories |
| Setup Cost | Extremely high if retraining the model | Affordable, requiring only database infrastructure |
Key Benefits of Using RAG for Enterprises
Using a retrieval framework gives enterprises several practical benefits when they deploy AI systems at scale. It helps organizations improve accuracy, maintain compliance, and manage business information more effectively.
-
Verifiable Source Citations: Because the model pulls answers from specific text chunks, it can tell users exactly which document, page, or paragraph it used to find the answer. This makes auditing AI outputs remarkably easy.
-
Enhanced Data Security: RAG systems can restrict information access based on user permissions. The retriever will only pull documents that the specific user has clearance to view, protecting sensitive corporate data.
-
Cost Efficiency: Training a custom language model from scratch costs millions of dollars in computing power. In contrast, setting up a vector database for retrieval costs a fraction of that amount and achieves superior accuracy for specific business tasks.
Frequently Asked Questions
Is ChatGPT a RAG model?
No, ChatGPT itself is not purely a RAG (Retrieval-Augmented Generation) model. It is a Large Language Model (LLM) developed by OpenAI. The core model learns from large amounts of data and can generate answers without searching external sources. It uses learned patterns and knowledge to understand questions and create responses.
However, the ChatGPT application can use RAG-like methods when it needs extra information. For example, when ChatGPT searches the web, reads uploaded files, or connects to external databases, it retrieves useful information and gives that context to the language model. This process improves accuracy and provides more updated answers. ChatGPT is an AI assistant powered by an LLM that can use retrieval systems, but it is not a RAG model by itself.
What is RAG in LLM with example?
RAG stands for Retrieval-Augmented Generation. It is an architecture that improves an LLM by connecting it with external information sources. Instead of depending only on training data, a RAG system finds relevant information from documents, databases, or websites. It then gives this information to the LLM to create a better response.
For example, an HR assistant AI may answer questions about employee healthcare plans. If an employee asks, “Does my insurance cover acupuncture?”, a normal LLM may not know the latest company policy. A RAG system searches the company’s benefits documents and finds the section about acupuncture coverage. The LLM then uses that information to create a specific and reliable answer.
What are the 4 stages of RAG?
The four main stages of RAG are data ingestion, retrieval, augmentation, and generation. In the data ingestion stage, the system collects documents, PDFs, or web pages. It breaks the text into smaller sections, converts them into vectors, and stores them in a vector database.
During retrieval, the system searches the database to find information related to the user’s question. In the augmentation stage, the system combines the retrieved information with the user’s prompt. Finally, during generation, the LLM uses this improved prompt to create an accurate and relevant response.
What is the difference between LLM and RAG?
An LLM is the core AI model, while RAG is a framework that improves how an LLM uses information. An LLM learns from large datasets and creates responses using its training knowledge. However, it may not know recent events or private information.
RAG connects an LLM with external sources such as documents, databases, or websites. When a user asks a question, the RAG system first finds useful information and gives it to the LLM. The model then uses this context to generate a more accurate answer. In simple terms, an LLM works like a brain, while RAG gives that brain access to a searchable knowledge library.
Can RAG completely eliminate AI hallucinations?
RAG can greatly reduce AI hallucinations, but it cannot remove them completely. A RAG system improves accuracy by finding relevant information and giving it to the LLM before it answers. However, mistakes can still happen if the system retrieves poor-quality data or if the model misunderstands the information.
Developers can reduce hallucinations by improving data quality, using better search methods, applying clear instructions, and limiting answers to trusted sources. RAG does not guarantee perfect results, but it makes AI responses more reliable. This makes it useful for areas such as healthcare, finance, and legal applications.
Conclusion
Answering the question of what Is Retrieval-Augmented Generation reveals that the future of artificial intelligence relies on grounding models in verifiable reality. Standalone language models possess incredible linguistic capabilities, but their tendency to hallucinate and their reliance on static data limits their utility in professional settings. By pairing these models with intelligent retrieval systems, organizations unlock the full potential of automation without sacrificing accuracy.
Implementing a retrieval pipeline transforms how systems interact with data. It converts isolated, frozen neural networks into dynamic tools capable of accessing real-time corporate knowledge bases, secure customer records, and public search engines. Consequently, users receive highly accurate, context-aware answers complete with verifiable citations.
As AI continues to evolve, retrieval-based approaches will play a major role in enterprise applications. RAG provides a practical, secure, and cost-effective way to build AI systems that people can confidently use. To understand how this connects with broader AI advancements, explore this guide on what is generative AI.


